Blog
Non-Determinism of Maps in Golang: Why, How, and the Consequences
May 6, 2026
Did you know that Golang map iteration is non-deterministic? When I first heard this, I couldn’t believe it. I thought to myself, "Computer instructions will run the same way every single time. That is what makes them computers." But if you run a simple test, you’ll be surprised that Golang map iteration is indeed different between runs. This program iterates over a map of three values, four times:
import "fmt"
func main() {
values := map[string]uint{
"a": 1,
"b": 2,
"c": 3,
}
for i := range 4 {
fmt.Printf("Iteration %d: ", i+1)
for key, value := range values {
fmt.Printf("%s=%d ", key, value)
}
fmt.Println()
}
}The output of the map varies between loop iterations. Below is an example output:
Iteration 1: a=1 b=2 c=3 Iteration 2: c=3 a=1 b=2 Iteration 3: c=3 a=1 b=2 Iteration 4: a=1 b=2 c=3
The first time I ran this code, I lost my mind. I had to understand why this is the case, how it’s implemented, and what the consequences of the non-determinism are. I hope you enjoy this rabbit hole on non-deterimism of Maps in Golang.
Why Is There Randomness?
Randomness on maps is a feature of Golang. Reading the specification for the language, this is explicitly documented:
The iteration order over maps is not specified and is not guaranteed to be the same from one iteration to the next.
Just because the specification the says it can be different between iterations does not mean it’s true in practice; but, in this case, it is. I reviewed various articles and GitHub issues to understand why this randomness in iteration is a decided-on feature of Golang. I came across two main reasons: freedom of implementation and Hash DoS Prevention.
Freedom of Implementation
Iteration over maps is an implementation detail; they do not want developers relying on the current ordering. For instance, what would happen if the underlying algorithm and storage mechanism changed? If they had to preserve the original ordering semantics, it would severely limit the changes that could be made to the language, even if the new implementation was faster or more efficient in some way. The Golang development team is giving themselves space in the future to improve maps.
So, how does Golang ensure developers don’t rely on the existing ordering semantics? By taking it explicitly random! It’s better to fail fast than to have code fail years later after a version change. After reading multiple blog posts about the reasons behind the decision, this appears to be the main reason for the randomness.
Denial of Service Prevention
A later section discusses the implementation details of maps in Golang. In general, maps are just hash maps that have O(1) lookup in the best case and O(N) in the worst case. If there’s a collision, then the entry is inserted into the next available slot. In 2011, Julian Walde and Alexander Klink had a clever idea: what if we create lots of hash collisions intentionally? By doing this, an attacker can turn the usual O(1) lookup into a very large number of computations by introducing many conflicting entries. This led to Ruby on Rails, ASP.NET, and many other application-level denial-of-service vulnerabilities at the time.
With random slots for hashing, an attacker cannot intentionally create collisions. So, this prevents the DoS attack. It appears that the Golang developers were aware of this bug class, and this may have influenced this decision as well.
How Does Randomness Work?
HashMaps Data Structure
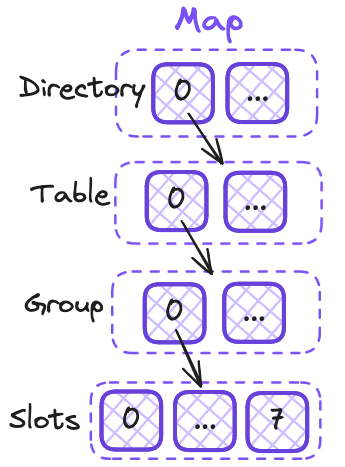
As of 2026, Golang uses a HashMap under the hood. To make it expandable and efficient, they use a deeply nested set of data structures. The data structures are as follows and are shown in Figure 1:
- Slot: A storage location for a single key/element pair.
- Groups: A group of 8 slots.
- Tables: A Swiss hash table. Contains one or more groups.
- Directory: The top-level data structure. Contains pointers to all of the tables.
From these data structures, it uses a hash of the key to determine which entry to use. The upper bits are used to select the appropriate table (the number of bits depends on the number of tables, and thus the total number of entries). The group uses bits 7-63. After this, the lower 7 bits of the hash are used to filter candidate slots within each group. If no match is found in the starting group, the map probes additional groups until a match is found or an empty slot is reached. This handles hash collisions where multiple keys map to the same slot.
This is a high-level overview of how the internals work, but it is sufficient for this blog post. If you want to learn more about it, please read Go Map Internals and Why Ordering Isn’t Stable by Alexander Obregon, or read the source code (which has great comments) directly.
Randomness
Randomness is introduced in two places: during map creation and iteration.
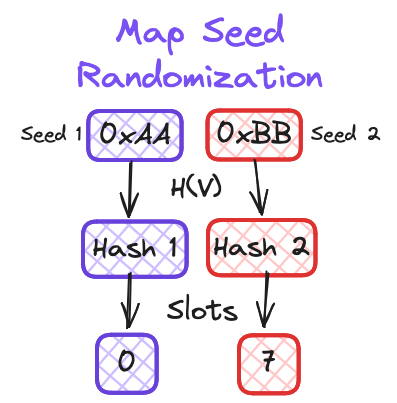
To find the proper location to store the key-value pair, a hash function is used. The hash contains two portions: the key for the entry of the map and a seed. This seed is randomly generated during map creation and used as part of the hash computation. So, by changing the data that the hash function uses, the distribution of the values changes within the map storage. In practice, this completely randomizes which slots are used to store data for each individual map creation, as shown in Figure 2. This solves both the hash DoS problem, and randomization on iteration as well in one change.
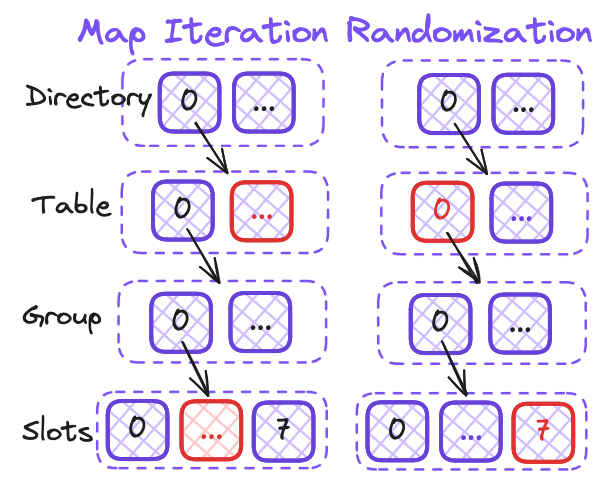
If this were the only source of randomness, iterating over the same map multiple times in a program would yield the same ordering. To make it truly different on each iteration, the iterator itself needs to have entropy. In practice, two random values are generated: one for the table index and one for the slot (but not the group, which makes it less random, as seen here if you’re curious). This creates non-deterministic iteration on maps by changing the starting point of the iteration. For a visual representation of this process, check out Figure 3.
Randomizing both the table indexing and the iteration start point makes it highly likely that a developer will notice the unintended behavior and do something else instead. Although it’s not perfectly random because of the missing group selection, it does do its intended job.
Consequences
The Go team retained the ability to modify the underlying map implementation and prevented hash-collision DoS attacks by using randomness on the hash key and on iteration. What were the design tradeoffs for this choice? While these decisions favor language evolution and runtime security, the resulting non-determinism introduces specific risks that are worth discussing.

The tradeoff of prioritizing internal flexibility and DoS protection is that it shifts the burden of determinism entirely to the developer. Iterating over map entries in a non-deterministic order can result in inconsistent outcomes across executions. While this behavior is an intentional design choice for the language, it creates a surface for logic errors if the developer assumes an ordering that Go explicitly does not guarantee. There are several articles online about this causing bugs.
Blockchains represent the most demanding use case for this tradeoff because their consensus mechanisms require absolute determinism. To reach an agreement, every node in the network must arrive at an identical state. If there is even a single bit of difference between the states, the resulting entity-level divergence can prevent consensus from being finalized, bringing the blockchain to a dead halt.
For blockchains written in Golang, non-determinism arising from map iteration is a common class of vulnerability documented in various blockchain security guides. Here are two issues that I found interesting:
- Thorchain Consensus Failure: Iterating over a map of values was done by each blockchain node. Because one of the entries was bad, the loop exited early. This led to different exit points on each node, resulting in different states and, thus, a consensus failure. The commit to fix this is aptly named
maps are evil. - JSONPath Wildcard Leads to Consensus Break: JSONPath is used for JSON filtering and supports maps. When using wildcards on maps to return values, the order of the returned data was non-deterministic because it relied on map iteration. This led to a consensus failure.
How To Iterate Over Go Maps
Determinism isn't always a requirement, but when it is, it’s absolute. Telling developers to simply avoid map iteration is a naive recommendation, as it may be the most practical approach in some situations. Instead of avoiding the tool, the goal should be to recognize the design tradeoff and manage the ordering ourselves when the situation requires it.
To do this correctly, you can follow a standard three-step pattern:
- Iterate through the map to populate an array.
- Sort the keys from the map in the array.
- Iterate over the contents of the array that contain the map entries.
This approach gives you a standard ordering by adding one extra step to your workflow. It’s a well-documented technique and remains the primary way to handle non-determinism of map iterations Golang. You can see the implementation in the code below:
package main
import (
"fmt"
"maps"
"slices"
"sort"
)
func main() {
values := map[string]uint{
"a": 1,
"b": 2,
"c": 3,
}
keys := slices.Collect(maps.Keys(values)) // 1
sort.Strings(keys) // 2
for i := range 4 { // 3
fmt.Printf("Iteration %d: ", i+1)
for _, key := range keys {
fmt.Printf("%s=%d ", key, values[key])
}
fmt.Println()
}
}There are some caveats to this process though. Sorting is an expensive operation. Only perform the sort if the ordering really does matter.
If you’re constantly using this function with a large number of keys, I would look for a different solution. Another way is to store the keys separately from the map's entries in an array. When iterating over the map, use the array entry as the key to the map. This will be deterministic because arrays are ordered. Read this example to see this in action.
Conclusion
The decision to use randomness in Golang map iterations is something I initially disagreed with because of the recurring vulnerabilities in Golang blockchains. After reading the source code and the rationale for the decision, I now completely understand the why and tend to agree with the change. Still, it is a curse that we’ll have to live with for the rest of time as software engineers.
Thanks for reading the post! I hope that you enjoyed this Golang rabbit hole and learned some new things from it. All of the code and references are provided in mdulin2/GoNonDeteriministicMaps GitHub repo. Feel free to contact me (contact information is in the footer) if you have any questions or comments about this article or anything else. Cheers from Maxwell "ꓘ" Dulin.




{kind=link}