Blog
Why I Fired My AI Security Assistant (Sort Of)
October 6, 2025
As Google, Stack Overflow, and now LLMs become embedded in our workflows, we must ask: are they currently enhancing problem-solving or diminishing critical thinking?
In this post, I’ll explore the trade-offs of incorporating LLMs into a security engineer’s toolkit. As someone who regularly performs code reviews, I’ve seen where these models can meaningfully accelerate tasks like code comprehension and tool creation. But I’ve also seen the subtler costs: the erosion of critical thinking when we rely too heavily on them. In this blog post, I'll discuss the pros and cons off LLMs and finish with how I personally integrate LLMs into my workflow to maximize their strengths without undermining technical rigor.
Strategic Applications of LLMs in Security Research
There are numerous compelling reasons why AI tools have become so popular, and they have transformed many industries in just a few years. While many industries use AI tools for a variety of tasks which do not need that level of firepower, I have found LLMs to be very helpful for white-box code reviews and see its power constantly growing.
Code Comprehension
In a security code review, the primary challenge in identifying vulnerabilities is understanding the code thoroughly. It is possible to search for surface-level issues, such as SQL injection from an easy-to-track source, without knowing the code very well, but this approach will only take you so far. Finding deep bugs in an application requires a profound understanding of the codebase. We mean more than just knowing what each function does; it involves grasping the architecture, data flows, module boundaries, side effects, performance trade-offs, and historical decisions that shaped the system. This level of insight allows engineers to trace non-obvious failure paths, form accurate mental models, and reason about the system's behavior under edge conditions. LLMs and static analysis tools have become quite proficient at understanding code, and we can leverage this to our advantage. This is where I personally get the most value from using LLMs.
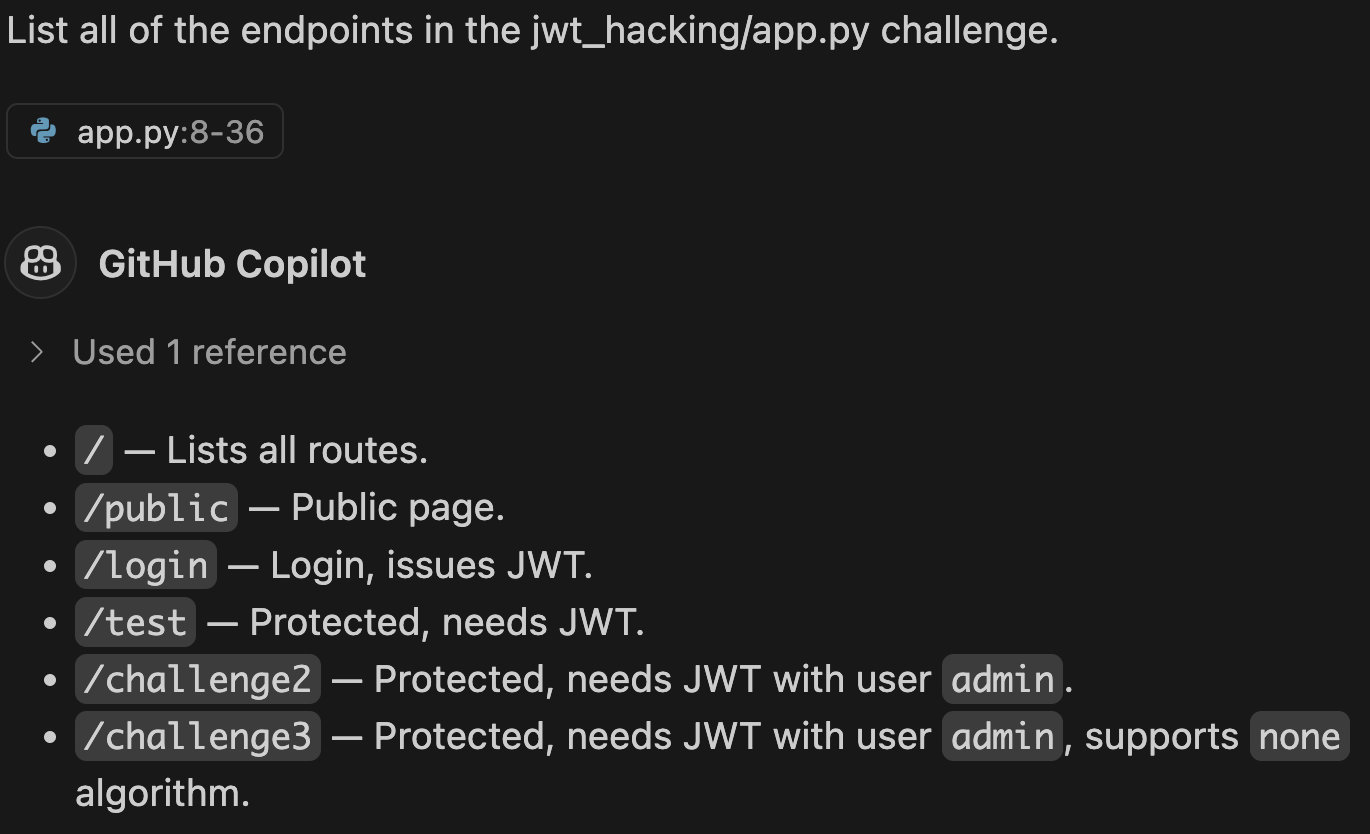
High-level architectural questions. Determining a project's file structure or tech stack often presents significant initial challenges. In complex codebases that utilize challenging-to-follow constructs (such as Golang channels), the lifecycle of calls can be especially complicated. Many AI tools excel at answering these questions, making it easier to start working on a new project. The primary tool that I use for high-level questions is DeepWiki. It's not perfect, but even if it is wrong, it guides me in the right direction. An example of this is shown in Figure 1.
When you are working deep inside a program's code, some parts may not be immediately clear. The purpose of a function or the way the code is written might be confusing. In such cases, tools like Cursor and CoPilot are highly effective for addressing narrowly focused code comprehension questions. These inquiries can be general, such as "Explain the functionality of the map method in JavaScript" or more context-specific, such as "What's the rationale for using map to perform type transformation within this block of code." Asking these types of questions prevents me from being stuck on a single issue for a long period of time.
A final application for enhancing code comprehension is a method of active self-assessment via quizzing. After studying a section of the code and becoming confident in my understanding, I'll ask the LLM a question and then attempt to answer it myself before it's generated. The goal is to see if my answer is the same as the AI's answer, similar to flashcards but dynamic. If the answers match, I feel confident in my understanding. If they do not, I work to understand the difference. This process helps gain confidence in my knowledge of the codebase.
Test Case Generation
Many security problems recur frequently. Since the LLM has an enormous amount of data to train on, it is great at generating a plan of attack. I find that generic LLMs like Gemini and ChatGPT are very good at generating test cases.
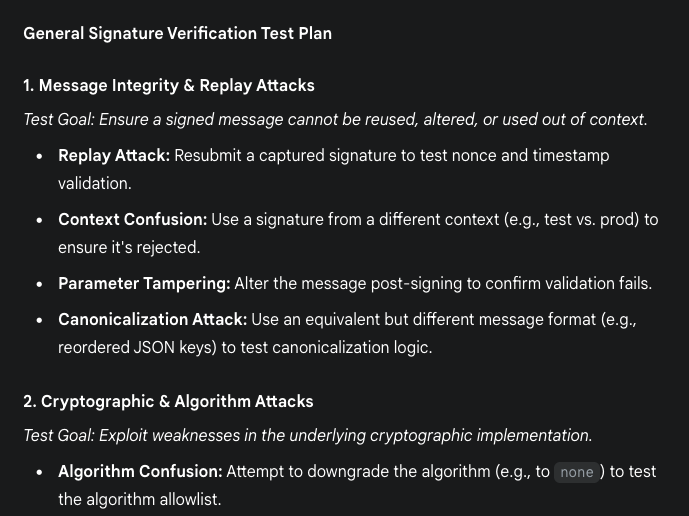
I primarily use targeted questions about how to test complicated sections of code after I've done my initial testing. As an example, I recently reviewed code that was verifying digital signatures. Digital signatures can fail in various ways complicated ways. An AI tool can generate a comprehensive list for me to consider, leveraging its vast knowledge pool. Many of them are incorrect but these can just be ignored. This isn't all of the tests to run, but it commonly creates novel ideas to try. I have personally identified several vulnerabilities utilizing this AI-assisted technique. An image showing this being done with Gemini is shown in Figure 2.
It is important to understand what this advice does not mean. I am not suggesting that you ask big, general questions like, "how to hack this website." These types of questions usually lead to answers that are not helpful. Additionally, blindly asking the LLM to find security vulnerabilities won't help much either. In general, the more specific you are the better for accuracy. The task of testing is still the responsibility of the human in the loop; don't have the LLM perform the testing for you.
Scripting
LLMs are very adept at generating code from scratch that works effectively for a given task. Although this is primarily a feature for developers, we can utilize it to our advantage as security researchers.
Writing Proof of Concepts (PoCs) is an integral part of vulnerability research. Most of the time, I know what I want to test, but not how to perform the test for the vulnerability on the system. So, I spend a significant amount of time fiddling around with pre-existing test suites, trying to understand them. It turns out that LLMs are really good at writing boilerplate code and getting you off the ground in these situations! By asking the LLM to get a basic setup, you can more quickly test for the real security issue. The more time you have, the more bugs you will be able to find in the long run.
Large Language Models are effective at quickly writing code for well-defined tasks outside of proof of concepts as well. Recently, I needed to identify all types used by recover() in Golang within a codebase. My options were to manually sift through all recover() calls in an error-prone manner or automate the entire process with a Golang linter. The former would have been error-prone, but both would have been time-consuming. Since I had previously written some Golang linters, I knew this was a good use case for one, but it would take a few hours of precious time to write. Going with the theme of this article, I asked Gemini to create the Linter for me, and it worked flawlessly from the first execution. This allowed me to identify all the types and continue my hacking pursuits, saving me hours of effort. There are a lot of other programming tasks you can automate with LLMs - the sky is the limit here.
Limitations and Risks of LLM Integration
A great deal has been written about the general flaws of LLMs. We've all seen the funny hallucinations, such as Google's AI suggesting glue on pizza, and we know they struggle with basic tasks like counting. But I'm not here to rehash those points. The focus here is specifically on their weaknesses in cybersecurity and within the human-in-the-loop aspect.
Reduced Learning
The reliance on Large Language Models (LLMs) for code analysis represents a potential local optimum in skill development if overused. When a problem's complexity exceeds the LLM's capacity, people will face a performance plateau. Critical code analysis remains an indispensable skill for any security professional. Consequently, excessive reliance on LLMs risks reduced skill development and atrophy of existing code comprehension. Overall, this leads to detrimental long-term consequences for a researcher's effectiveness.

A hidden cost of many tools programmers use is that they reduce learning. If you can find an efficient sorting algorithm on Stack Overflow, why would you ever need to write your own? The reason is simple: personal capabilities. If you can't do the simple things on your own, then you will never be able to do the complicated things when called upon. The book PoC || GTFO has a story titled "Build your own f***ing birdfeeder" that demonstrates this perfectly. It tells the story of Howard Hughes, a man who built everything himself from a young age - from motorbikes to planes. One day, the United States approached him about creating custom equipment to recover a submarine from the ocean floor. Was he able to do it? Of course! Howard had spent his life building his own tools, which prepared him for this unique challenge. Again, if you can't do the simple things on your own (like build a bird feeder), then you will never be able to do the complicated things when called upon.
A balance between efficiency and learning must be carefully managed. For example, several of the images in this post are AI generated but I'm happy with that. I have no ambitions on being a great digital artist in the future; I just wanted some nice images. The important thing is to choose wisely: decide when a task is a good opportunity to learn, and when it is better to use an existing tool to solve the problem and continue on with your life.
Less Intimate Familiarity with the Codebase
Tools like DeepWiki are invaluable for understanding codebases in open-source projects. CoPilot, Cursor, Claude Code and others are also great for understanding specific code snippets. Again, there's a hidden cost to these tools: they can create a superficial understanding of the codebase in your mind.

Let's take the example of understanding authentication in an application. If you ask an AI tool how an application checks the user identity, it may or may not provide a basic, correct answer. The problem is that this answer leaves out important information. It won't inform you about the specific design patterns used for security, such as whether checks are built-in and automatic, or whether a programmer must manually add it to every new feature. Vulnerabilities are often found in these small details. This deep, personal knowledge of the code is also how an expert develops their intuition. Using AI tools to summarize code causes you to miss these critical insights.
When searching through the code to understand how one thing works, you may come across completely unrelated functionality that catches your eye. It's not directly related to your original goal, but every little piece of information paints a better and better picture of the application. This helps you connect the dots when one part of the application looks vulnerable because of something in another part of the codebase. This memory is lost when using LLMs solely for understanding. Don't be like the kid in Figure 4.
The solution to this is unintuitive: don't start with the LLM. Bring it in only when you're genuinely stuck or need a second opinion on your work. A recent study on thinking ability has shown this. The people who performed best were those who used their own minds first, and then used tools like Google Search and LLMs later. The key insight is that we want our brains to do the heavy lifting and deep thinking, and only then use the AI as an assistant. Even before the dawn of LLMs, this was well documented in the book Deep Work.
Context in Large Codebases
There have been some posts about "hackbots" like xbow and one-off posts about finding bugs, but fewer than I had expected at this point. Why is this? I believe that LLMs are not currently capable of understanding all code flow nuances in a codebase.
I am the main organizer of a Capture the Flag competition where I write 70% of the CTF challenges. When Cursor and CoPilot first came out, I tried identifying vulnerabilities in the years challenges using the LLMs. To my surprise, it found almost every single solution on its own. Even crazier, it found an unintended solution to one of the challenges. I believe it did well because of how small all of these challenges are.
In the real world, code is not as cut-and-dry as a CTF. Real-world codebases are vastly complicated. An LLM might find a SQL injection in code where, in reality, the user has no meaningful control over the input. It can't trace the actual path to exploitation in a massive codebase because it fundamentally misunderstands the constraints it's working under. Almost all "vulnerabilities" that LLMs have identified thus far have been false positives, which has been coined AI Slop.
A further limitation is the LLM's inability to comprehend the security assumptions and invariants that define a codebase's architecture. A function may exhibit characteristics of Remote Code Execution (RCE), but this may be intended functionality, deliberately exposed only to privileged administrative roles (a pattern familiar in extensible platforms like WordPress). This does not constitute a vulnerability within the established threat model. However, an LLM, lacking the capacity to interpret this crucial contextual framework, will invariably misclassify such a feature as a critical security flaw.
As LLMs become better at storing more context, they'll improve significantly at analyzing code for security issues. I have identified two vulnerabilities through a source code review in Cursor, but they are among a large number of false positives. For now, it is best to ask very targeted questions about a small section of code, rather than using a general command on the entire codebase. Before reporting anything, ensure that you truly understand the potential vulnerability that the LLM gives you.
Mindful Framework for Using LLMs in Security Reviews
Given the previously discussed cognitive costs, how can we leverage the benefits of LLMs while mitigating the inherent risks? These two objectives may appear mutually exclusive. The solution, however, lies in the careful application of these tools, governed by precise timing and moderation. My high-level process is as follows:
- Get a high level understanding of the codebase. I usually read the docs and use DeepWiki for high-level flow and organization of a codebase.
- A careful, line-by-line review of the code is the most important step. This part of the process should account for approximately 95% of the time you spend understanding the program. This detailed work is necessary to gain a comprehensive understanding of the code.
- Ask CoPilot, Cursor, or another tool when extremely stuck. Use this sparingly.
- Check your understanding of a code section by having a conversation with the AI tool. Gives you confidence in your understanding of the codebase.
- Hunt for vulnerabilities. Generate test cases from LLM sparingly.
- Confirm vulnerabilities with the LLM. Only use this as a heuristic.
When first entering a codebase, it can be quite intimidating. My first move isn't an LLM; it's reading the official docs to understand the project's intended purpose. The next step is where the LLMs first become useful - getting a high-level understanding of the codebase. Tools like Deep Wiki are great at explaining concepts such as the structure of a codebase, the tech stack being used, and the normal flow of operations. Remember, this is only a cursory glance, we don't want to get a false sense of our own comprehension of the codebase.
The subsequent phase is a systematic, line-by-line review. This is where you need to feel the grind and do some real deep work, with your brain firing on all cylinders. There's no shortcut here; getting your hands dirty is how you develop a real instinct for this stuff. If you're spending too much time using LLMs in this stage, you are only robbing yourself. Only when you get completely stuck should you turn to an LLM tool like Cursor to unblock you on a complicated section of code. Once happy with the understanding of the code base, you can validate comprehension by using the self-assessment technique.
In this final step, you will look for security weaknesses. First, use only your own knowledge to find problems. This should be the bulk of your time. Once you have exhausted your test cases, consider asking a general-purpose LLM like Gemini for new ideas. This allows your brain to function at its best, but still receive some support for optimal coverage. Eventually, I bet you'll find some vulnerabilities!
Conclusion
If you're new to using LLMs for security, I hope this opens your mind to how they can seriously upgrade your skills. If you already use these tools a lot, I hope this has opened your eyes to the long-term problems they can cause. The real takeaway of this article is one as old as time: all things are good in moderation. Excessive usage of an LLM can lead to long-term losses in cognitive ability and a false sense of coverage. Too little usage reduces your efficiency. Somewhere in the middle is the perfect amount of usage that you will need to find for yourself. This post is where I have currently settled, but it may be different for you.
Feel free to contact me (contact information is in the footer) if you have any questions or comments about this article or anything else. Cheers from Maxwell "ꓘ" Dulin.



