Blog
House of IO - Heap Reuse
October 16, 2021
Introduction
Exploiting heap based vulnerabilities tends to be difficult, complex and requires a deep knowledge of the library itself. As years go by, new techniques are discovered for exploiting the allocator, as well as changes being made to make the allocator more secure. The never ending cat-and-mouse game that is cybersecurity.
In 2020, several techniques were published in the House of IO that required rare primitives to achieve. Among these, the House of IO - Underflow allowed for the returning of arbitrary memory addresses from Malloc with a buffer underflow vulnerability. This could even bypass pointer mangling/encryption! In his article, we will discuss a primitive improvement to the House of IO - Underflow that may be useful in real world exploitation: a single buffer overflow with careful heap alignment. A proof of concept can be found at House of IO - Heap Reuse if you would like to follow along.
Chunks

- prev_size: The size of the previous chunk. This section is only used when the previous chunk is free.
- size: The size of the memory being given back to the user program. The first three bits include metadata of the chunk: prev_inuse (if the previous chunk is in use), mmap (is the allocated chunk using mmap) and n on-main arena (if the chunk is in a non-main arena).
- Fd: When chunks are free, they are stored within a linked list. The Fd is the forward pointer in the linked list when a chunk is in a bin. This field is only used when a chunk is free.
- Bk: Backward pointer in the linked list for when a chunk is in a bin. This field is only used when a chunk is free.
Bins - TCache
Bins
When using Malloc, chunks that are freed are put into a local storage to be reused. The storage locations for the free chunks are called bins.
There are a multiple types of bins for different sizes and situations within the allocator. All bins use a linked list data structure in order to keep track of the free chunks in the bin. For the purposes of this technique, only a single bin needs to be understood: TCache.
TCache Bin Chunks
The Thread Cache (TCache) Bins are a collection of bins for that are scoped per thread. TCache Bins have a unique bin for chunks from 0x20-0x410 (64-bit, which is assumed for this article) in groups of 0x10 bytes. When trying to get memory with a call to Malloc, the TCache is the first place that the allocator will look for chunks at.
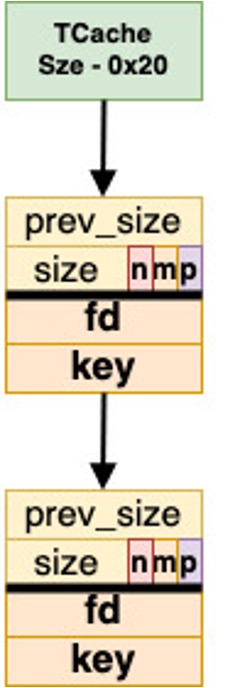
TCache Bins use a singly linked list in order to keep track of the chunks in a bin. This means that free chunks only have a single pointer to the chunk in front of it ('fd' field in Figure 2). This is the storage functionality for chunks mentioned above. TCache Bin chunks do not have the bk field as a back pointer, since it is a singly linked list. Instead, it uses this field as a double free protection called key, which can be seen in Figure 2 as well.
TCache Bin Data Storage
The data structure for storing the TCache Bin information has two fields: counts and entries. The C struct tcache_perthread_struct is shown below:
typedef struct tcache_perthread_struct
{
uint16_t counts[TCACHE_MAX_BINS];
tcache_entry *entries[TCACHE_MAX_BINS];
} tcache_perthread_struct;
The entries field is an array of pointers to the beginning chunk in the linked list of free chunks. Since this is an array, each value represents a pointer to a specific size. For example in Figure 2 the green box is a pointer to the first chunk in the 0x20 TCache Bin. The counts field is an array that keeps track of the amount of chunks inside of each bin, with the default limit being 7.
The index of the array for both fields (entries and counts) is dependent on the chunk size being used, which is calculated using a fancy macro to go from size to index. The TCache Bin itself is allocated on the heap in a per thread manner on the first heap allocation of the thread. It should be noted that from 2.26-2.29 the counts array was of type char, which changes the size of the struct in memory.
Only the TCache Bins are necessary for understanding how this technique works. However, this article only scratches the surface of how the allocator works for bins and chunks. If you want to learn more about the allocator, Azeria Labs and Sploitfun have awesome articles on this.
Arenas
Arenas are a struct which contains references to the heap, the bins (where the free chunks are stored at) and other state information about a heap. Threads assigned to each arena will allocate memory from that arena's free lists. In layman's terms, the arena is the metadata information that makes the allocator work. All of this state information is stored in the malloc_state struct.
A single threaded process has a single arena called the main arena. When threads become involved, multiple arenas are used in order to allow for concurrent heap data access, as heap data is specific to a process. These other arenas are called non-main arenas, which is what the n bit on the chunk size is used for. After so many threads have been created, the threads begin to share the arenas, which means they share the heap memory.
Fd Poison Attack & Remediation
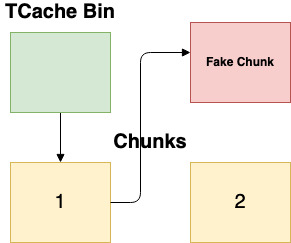
LibC and the .bss with no validation on the memory location what-so-ever. A visual representation of this attack can be seen in Figure 3 with the Fake Chunk (in red ) representing the overwritten fd pointer.
This attack works in both the TCache and Fastbin, but is significantly easier in the TCache because of a properly sized chunk field being needed for the Fastbin. Regardless, this attack is trivial to pull off with a use after free on a singly linked list. Because there is only one pointer, verifying the legitimacy of the pointer is incredibly hard to do. This is where Checkpoint Research comes in!
Safe Linking (Pointer Mangling)
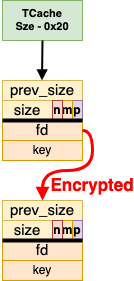
In 2020, researchers from Checkpoint implemented Pointer Mangling into GLibC Malloc. Pointer Mangling mangles/encrypts the fd pointers to make a simple overwrite of the fd pointer no longer possible. This is done by XORing the fd pointer with the storage location of the pointer shifted 12 bits. As a bi-product of this, the encryption key is essentially ASLR. A visual on the mangling/encryption in action can be seen in Figure 4. Besides the encryption, additional alignment protections were put in place to make relative overwrites not be as effective.
The exact details of pointer mangling are not important for this article; just the existence of this feature. As a result, this is all that will be covered in this article on pointer mangling. For more information how the mangling process works, read Analysis of New Malloc Protections on Singly Linked Lists.
According to the threat model of Checkpoint, the protection only works if the heap ASLR is still in place, since the pointers are mangled/encrypted using the heap slide as the secret information. If an attacker knew the heap slide, then they could encrypt their own pointers. So, this begs the question: "If the heap slide is unkonwn, is it possible to bypass this protection?"
House of IO
The House of IO uses two distinct tricks to bypass pointer mangling:
- The key field, used for double free protection, is a pointer to the TCache itself, prior to 2.34. This is used in the the House of IO - Free Management Struct and House of IO - UAF.
- The TCache Bin data structure stores the initial pointers unmangled/unencrypted. This is used in the House of IO - Underflow.
Our interest lies in the latter insight; the TCache Bin information (tcache_perthread_struct) stores the heap pointers at the beginning of the heap unmangled/unencrypted. The mangling process only happens on the fd pointers actually inside of the chunks. In Figure 4, notice that the arrow going from the bin to the first chunk is unencrypted while the pointer from the first chunk to the second chunk is encrypted. So, why is this a problem?
The TCache Bins are stored within the heap itself! In GLibC 2.26+, the first allocation on the heap for a specific thread will trigger the TCache Bin structure (tcache_perthread_struct) to be allocated. After the TCache Bin structure chunk has been allocated, the memory from the original allocation request is returned. This means that the first allocation on a given heap is always the TCache Bin data structure. Since the Bin information is stored on the heap, what if we wrote to the bin pointer directly?
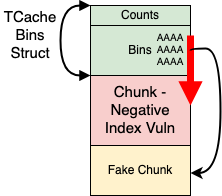
House of IO - Underflow
The House of IO - Underflow does exactly this! It uses a buffer underflow (negative indexed write) vulnerability in order to write a malicious chunk (memory address) into one of the TCache Bins. Since we edited the fd pointer directly, as far as the allocator is concerned, this is now the first pointer of the linked list (head pointer). Since these entries are not mangled/encrypted, our fake chunk will be returned to us after a single allocation with no problems. Hurray!
An example of this attack can be seen in Figure 5. The first chunk (in green) is the TCache Bins struct and the second chunk (in red) is the chunk with the buffer underflow vulnerability, which is represented with the thick red arrow. From this overwrite, we are able to point one of the TCache Bin entries to an arbitrary address in memory, which will be returned by the allocator.
Although this attack is impactful, the primitive is fairly rare. Being able to write to an arbitrary offset in the negative direction just doesn't happen very much. In the post itself, the author says "Statistically speaking (at least from our experience), an underflow is by far less common than a plain overflow vulnerability."
Reusing Heaps Between Threads
Since the House of IO - Underflow is so impactful, but requires a rare primitive, the goal was to make the exploit primitive more commonplace, such as a traditional buffer overflow or a use after free. The original variation for this attack uses the buffer underflow to perform the attack on the TCache Bins because it is stored as the first allocation on a heap. But, does this have to be the case? No, it does not! This is the novel section of the article with everything else being review on previous techniques and knowledge.
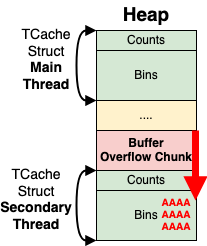
As mentioned in the Arena section, the Arenas (which contain the heap memory pointer) can be shared between threads! By default, the number of arenas is capped at eight times the number of CPUs in the system. This setting can be changed via the mallocopt (Malloc Options) function or via the MALLOC_ARENA_MAX environmental variable. This becomes relevant because the TCache is stored per thread on the heap.
If we can get a thread that shares the same memory with another thread, then the TCache Bin data structure will not be the first allocation on the heap! Instead, it will be treated as a normal heap chunk in the program and can be anywhere within the heap. Since the chunk can be in the middle of the heap, all exploit primitives are back on the table for overwriting one of the TCache Bin pointers! A use after free, double free or standard buffer overflow will do the trick. No more buffer underflow vulnerabilities are required for this!
In Figure 6, there is a chunk vulnerable to a buffer overflow. Since the TCache Bin struct for the Secondary thread is allocated after our vulnerable chunk, it can be exploited just like any other chunk. In Figure 6, the red A's and big red arrow represent a buffer overflow going into the TCache Bin structure, corrupting the storage system for the bin itself. This means we have improved the exploit primitive for the House of IO!
Attack Flow
This technique requires a standard heap exploitation primitive, such as a use after free, heap overflow or a double free. However, the difficult aspect of this technique is setting up the heap properly for this to attack to work. The steps for the exploit technique are shown below with each section explained in depth further down:
- Heap Feng Shui: Organize the heap in such a way that we can attack the TCache Bin struct allocation. This can be a pointer ahead of our vulnerable chunk for a buffer overflow or the same chunk for a use after free.
- TCache Bin Struct Allocation: Place the new threads TCache Bin struct onto the heap. This will allow us to overwrite it with a standard primitive.
- Corrupt Bin Pointer: Overwrite or set a pointer in the TCache Bin.
- Allocate Fake chunk: Once the chunk has been removed from the allocator, the program believes it is valid memory. Hence, we can write to any address we choose!
Heap Feng Shui/ TCache Bin Struct Allocation
This attack can use a use after free, double free or a heap buffer overflow vulnerability to corrupt the TCache Bins. However, for the sake of this article, we are going to assume a single continuous buffer overflow on the heap for the primitive. As a result of the selected primitive, the goal is to get a chunk vulnerable to a buffer overflow directly before the chunk used for the TCache Bins allocation. This way, when we overflow our buffer, we can use it to corrupt the TCache Bins. For all of these sections, please review Figure 5 for the ideal setup.
Allocation Setup Considerations
First, two threads need to share the same heap memory. This can be done by creating a thread count larger than
eight times the number of CPUs in the system, changing the max arena count set via the mallocopt (Malloc Options) function or via the MALLOC_ARENA_MAX environmental variable. Once two threads share the same heap memory, we can begin our attack.
While using the buffer overflow, the main goal is to get the TCache Bin chunk directly after a chunk that we can use for the overflow. This requires creating holes in the heap that can be filled or making requests at the perfect times between the threads for the overflow later. In practice, there are some gotchas though:
- When calling
pthread_createan allocation of size 0x120 occurs on the heap of the thread creating the new thread. Hence, if only using two threads, creating a chunk in the main thread then expecting the next allocation to be the TCache struct in the secondary thread will simply not work because of the thread information on the heap. - The TCache Bins allocation is of size 0x290, since this is in GLibC Malloc 2.31. If trying to fill the hole by freeing a chunk in the main thread to be used in the secondary thread, this will go directly into the main thread's TCache Bin, resulting in the secondary thread not having access to this. Further feng shui to get the chunk into the unsorted bin, small bin or large needs to be performed to line up the heap properly.
- The TCache Bin Structure is only allocated to the heap on the first heap allocation of the thread. Hence, at least one allocation in the thread needs to be performed first in order to perform this technique.
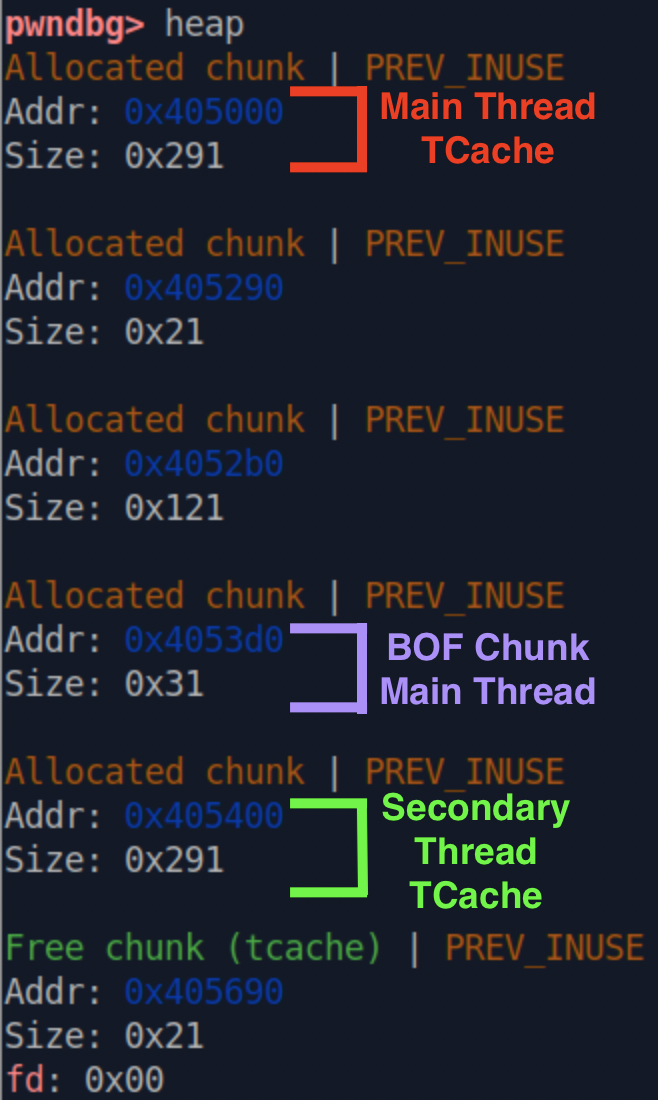
Example Setup
In the linked proof of concept, two threads (aptly named main thread and secondary thread) and limited the amount of arenas to one via the mallocopt function. But, in a real application, an arena exhaustion technique would be needed to be used to perform this exploit. The full test setup, prior to corrupting the TCache Bin Pointer, is shown below and within Figure 7:
- In the main thread, create a heap chunk. This will initialize the heap for the arena and add the TCache Bin struct for the main thread. The TCache Bin Struct for the main thread is the red text in Figure 7. The 0x20 sized chunk directly below the Bin is from the heap allocation made in this step that was used to trigger the TCache Bin struct creation.
- Create a new thread, which will be known as the secondary thread. When this thread is created, an allocation of size 0x120 is put onto the heap of the main thread.
- In the main thread, create a heap chunk. This chunk will be after the thread information mentioned above and will be the chunk with the heap overflow vulnerability. This is the purple text in Figure 7 and labeled BOF Chunk Main Thread. By allocating this chunk after the creation of the new thread, we avoid gotcha #1.
- In the secondary thread, allocate a chunk of size 0x20. This will initialize the TCache Bin Struct for this thread into the same heap as the main thread. The new TCache Bin structure is in green in Figure 7. This avoids gotcha #2 because this takes memory from the top chunk instead of one of the bins.
- In the secondary thread, free the chunk from the previous step. This puts a chunk into the TCache that can be removed later and increments the count for the 0x20 TCache Bin. Although this step is not strictly required (as we can write to the counts itself), keeping the TCache Bins in a stable state is a wise decision to prevent the program from crashing.
Where does this allocation series leaves us? A chunk in the main thread sits directly below the secondary threads TCache Bin. Now, we are perfectly setup to perform the overflow!
Corrupt Bin Pointer
We have successfully put the TCache Bin structure in front of our chunk that is vulnerable to a buffer overflow. But, where do we write to? How far into the bin do we write?
There are two elements to the struct that holds the TCache Bins: counts and entries (bins) in this order in memory. The counts array takes up 0x80 bytes of memory while the entries take up 0x200 bytes. We will talk about these individually below.
Dealing with Counts
The counts array keeps track of the amount of pointers in a given bin. If this is set to 0 in GLibC 2.30+, then the allocator believes that there is no pointer there. Hence, if we want to get a malicious pointer into one of the TCache Bins (entries in the struct), then we will need to set the proper count as well.
What happens with our continuous overflow though? Do we need to be able to write NULLbytes? From empirical testing, the allocator does not do any validation on the count for a bin. As a result, writing a large amount of filler A's will suffice for a continuous buffer overflow. The key is that the fake chunk we are trying to get from the allocator has a count greater than 1, which can be done by freeing a chunk in the target TCache Bin or overwriting the count directly.
Writing the Fake Pointer

In order to use a continuous buffer overflow, we will need to write 0x10 bytes (for the metadata of the chunk) then 0x80 bytes to get to through the counts. From the final controlled byte of our vulnerable chunk, the overflow must be 0x90 bytes.
Once at the overflow point, the pointers are 8 bytes in size each. This means that for the chunk size that we want to overwrite, we need go up in groups of 8 bytes until we have reached the selected chunk, starting from a chunk size of 0x20. The formula for calculating the amount of bytes is Bytes = ((chunk_size - 0x20)/0x10) * 8. For instance, a chunk size of 0x80 would be ((0x80-0x20)/0x10) * 8 = 0x30 bytes. In the example proof of concept, the 0x20 bin (first bin in the TCache) is used, which has an index of 0.
Once we have found the address of the proper bin to write to, we need to write our target address to this location. As mentioned before, these pointers are not mangled/encrypted, making them straight forward to overwrite. This now functions like original Fd Poison attack mentioned above prior to pointer mangling. Eventually, when we allocate the chunk of the same size, our target address will be removed from the allocator and the user will be able to write to this location, turning this into an arbitrary write primitive! An example of how this looks can be seen in Figure 8 with the variable important_string being our target address in the .bss.
It should be noted that there are no restrictions on this address in terms of location. This can be in LibC, the .bss section and anywhere else. Additionally, this pointer is not bound by alignment checks of 0x10 bytes on 64-bit binaries, like the normal fd pointers of the TCache.
Allocate Fake Chunk
Setting up this attack, as shown above, is the challenging part. Once the attack has been setup, with the malicious pointer written in the TCache Bin, removing the chunk only requires a request of the proper size to remove. In the proof of concept, our fake chunk is in the 0x20 TCache Bin. As a result, a request to malloc(0x10) will return our fake chunk from the allocator.
At this point, we have returned an arbitrary memory address from the allocator. Since this gives us a WRITE-WHAT-WHERE primitive, this is essentially gameover for an attacker. To make this attack even better, if NULLbytes can be written in the payload, you can use this attack on multiple different bin sizes at the same time! Hence, it gives you multiple write opportunities. Even with a single write, a function pointer could be overwritten to start a COP or ROP chain to take complete control of the process.
Pros & Requirements
Overall, this technique is pretty devastating but is extremely technical and tedious. Below are the pros and cons of executing this technique:
Pros
- Bypasses pointer mangling for the classic fd poison attack.
- Relative overwrites on the heap pointers in the TCache Bin data structures can be used to bypass heap ASLR.
- Multiple fake pointers can be written to the TCache Bin, if NULLbytes can be used. This allows for multiple write primitives.
- Added improvement and flexibility on the required exploit primitive, when compared to the original House of IO - Underflow.
Cons
- Practically, the settings for the arenas do not make it trivial to reuse heaps. This means that a way to exhaust threads for a process in the application is required. This is the biggest ask of this technique.
- A leak for another address, such as LibC, .bss or other sections of memory may be required.
- If a continuous write is done from the bottom of the chunk, this destroys the TCache
countsarray. From this point on, all bins will have chunks in them, according to the allocator. Continuing with the heap in this state will likely crash the program very quickly unless special precautions are taken.
Conclusion
This exploit technique gives us more flexibility in the vulnerability class (UAF, heap buffer overflow, etc.) but requires that the heap memory is reused between threads for a variation of the House of IO. Both the House of IO - Underflow and the House of IO - Heap Reuse have their pros and cons, but one thing is for certain: the more options you have the better. This new technique may work in situations with lots of threads and a standard vulnerability, while the other may work in other cases where only a buffer underflow is found. The key insight here is that the TCache Bin data structure does not mangle the pointers and this can be exploited in modern binaries.
Heap exploitation techniques are awesome, but vastly complex. Because of this, I created a workshop called the House of Heap Exploitation that is still being actively developed and taught at various conferences. Additionally, I post fairly consistently about security stuff (especially heap exploitation) and contribute to the how2heap repository whenever something interests me. This blog now has an RSS feed as well.
Major shoutouts to Awarau for the original technique description, Kevin Choi for reviewing this article and the people/organizers of ToorCon for being an awesome place to do my training. Feel free to reach out to me (contact information is in the footer) if you have any questions or comments about this article, have conference suggestions or anything else. Cheers from Maxwell "ꓘ" Dulin.



