Blog
Non-Determinism of Maps in Golang: Why, How, and the Consequences
May 6, 2026
Did you know that Golang map iteration is non-deterministic? When I first heard this, I couldn’t believe it. I thought to myself, "Computer instructions will run the same way every single time. That is what makes them computers." But if you run a simple test, you’ll be surprised that Golang map iteration is indeed different between runs. This program iterates over a map of three values, four times:
import "fmt"
func main() {
values := map[string]uint{
"a": 1,
"b": 2,
"c": 3,
}
for i := range 4 {
fmt.Printf("Iteration %d: ", i+1)
for key, value := range values {
fmt.Printf("%s=%d ", key, value)
}
fmt.Println()
}
}The output of the map varies between loop iterations. Below is an example output:
Iteration 1: a=1 b=2 c=3 Iteration 2: c=3 a=1 b=2 Iteration 3: c=3 a=1 b=2 Iteration 4: a=1 b=2 c=3
The first time I ran this code, I lost my mind. I had to understand why this is the case, how it’s implemented, and what the consequences of the non-determinism are. I hope you enjoy this rabbit hole on non-deterimism of Maps in Golang.
Why Is There Randomness?
Randomness on maps is a feature of Golang. Reading the specification for the language, this is explicitly documented:
The iteration order over maps is not specified and is not guaranteed to be the same from one iteration to the next.
Just because the specification the says it can be different between iterations does not mean it’s true in practice; but, in this case, it is. I reviewed various articles and GitHub issues to understand why this randomness in iteration is a decided-on feature of Golang. I came across two main reasons: freedom of implementation and Hash DoS Prevention.
Continue Reading →
Across Solana Event SpoofingExternal
April 22, 2026
IBC Client Confusion on Neutron ICQ
March 2, 2026
Verifying state information across blockchains requires rigorous proof validation. In 2024, Nathan Kirkland and I identified a vulnerability in Neutron’s newly launched Interchain Queries (ICQ) module that compromised its proof verification logic without any fancy cryptography. By exploiting this weakness, an attacker could inject forged transaction proofs into the ICQ pipeline. This would have enabled the spoofing of arbitrary transactions for Neutron applications, leading to a variety of impacts depending on the application.
Neutron is a Cosmos SDK blockchain with support for CosmWasm smart contracts. I enjoy the Cosmos ecosystem and have done previous research into it, such as an RCE and an Infinite Mint. The following post breaks down how IBC ICQ works, the mechanics of the proof bypass, and the steps that an attacker could have taken to exploit it.
Inter-Blockchain Communication (IBC)
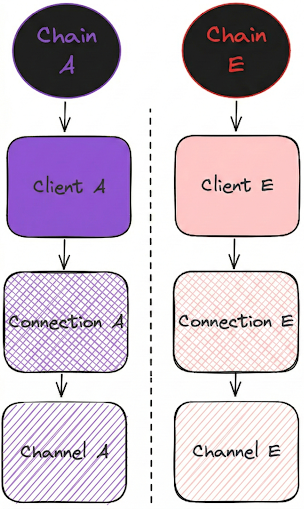
IBC (Inter-Blockchain Communication) is a light-client-based protocol for exchanging information between sovereign blockchains. While native to the Cosmos ecosystem, it is an agnostic standard. Chain interactions are permissionless, allowing applications to communicate and route arbitrary data through dedicated channels. Under the hood, this transport layer relies on a client-connection combination: the light client cryptographically verifies the state of a specific counterparty chain, while the connection establishes the secure, negotiated link between them. To see this relationship, review Figure 1.
In IBC, the client object holds the consensus state of a counterparty chain. This includes block heights, state roots, the current validator set, and other data required to mathematically verify Merkle proofs via light clients.
A connection is built on top of this client. Rather than just tracking state, a connection represents a stateful, negotiated agreement between two chains. It establishes the specific IBC version and features they will use to communicate, and is strictly tied to a specific client to verify those interactions. In practice, a connection is a slight abstraction of a client, but they are mostly the same thing.
The full details of how IBC works are out of scope for this article, but this should be sufficient context to understand the vulnerability. To learn more about IBC, read about it here.
Continue Reading →
Why I Fired My AI Security Assistant (Sort Of)
October 6, 2025
As Google, Stack Overflow, and now LLMs become embedded in our workflows, we must ask: are they currently enhancing problem-solving or diminishing critical thinking?
In this post, I’ll explore the trade-offs of incorporating LLMs into a security engineer’s toolkit. As someone who regularly performs code reviews, I’ve seen where these models can meaningfully accelerate tasks like code comprehension and tool creation. But I’ve also seen the subtler costs: the erosion of critical thinking when we rely too heavily on them. In this blog post, I'll discuss the pros and cons off LLMs and finish with how I personally integrate LLMs into my workflow to maximize their strengths without undermining technical rigor.
Strategic Applications of LLMs in Security Research
There are numerous compelling reasons why AI tools have become so popular, and they have transformed many industries in just a few years. While many industries use AI tools for a variety of tasks which do not need that level of firepower, I have found LLMs to be very helpful for white-box code reviews and see its power constantly growing.
Code Comprehension
In a security code review, the primary challenge in identifying vulnerabilities is understanding the code thoroughly. It is possible to search for surface-level issues, such as SQL injection from an easy-to-track source, without knowing the code very well, but this approach will only take you so far. Finding deep bugs in an application requires a profound understanding of the codebase. We mean more than just knowing what each function does; it involves grasping the architecture, data flows, module boundaries, side effects, performance trade-offs, and historical decisions that shaped the system. This level of insight allows engineers to trace non-obvious failure paths, form accurate mental models, and reason about the system's behavior under edge conditions. LLMs and static analysis tools have become quite proficient at understanding code, and we can leverage this to our advantage. This is where I personally get the most value from using LLMs.
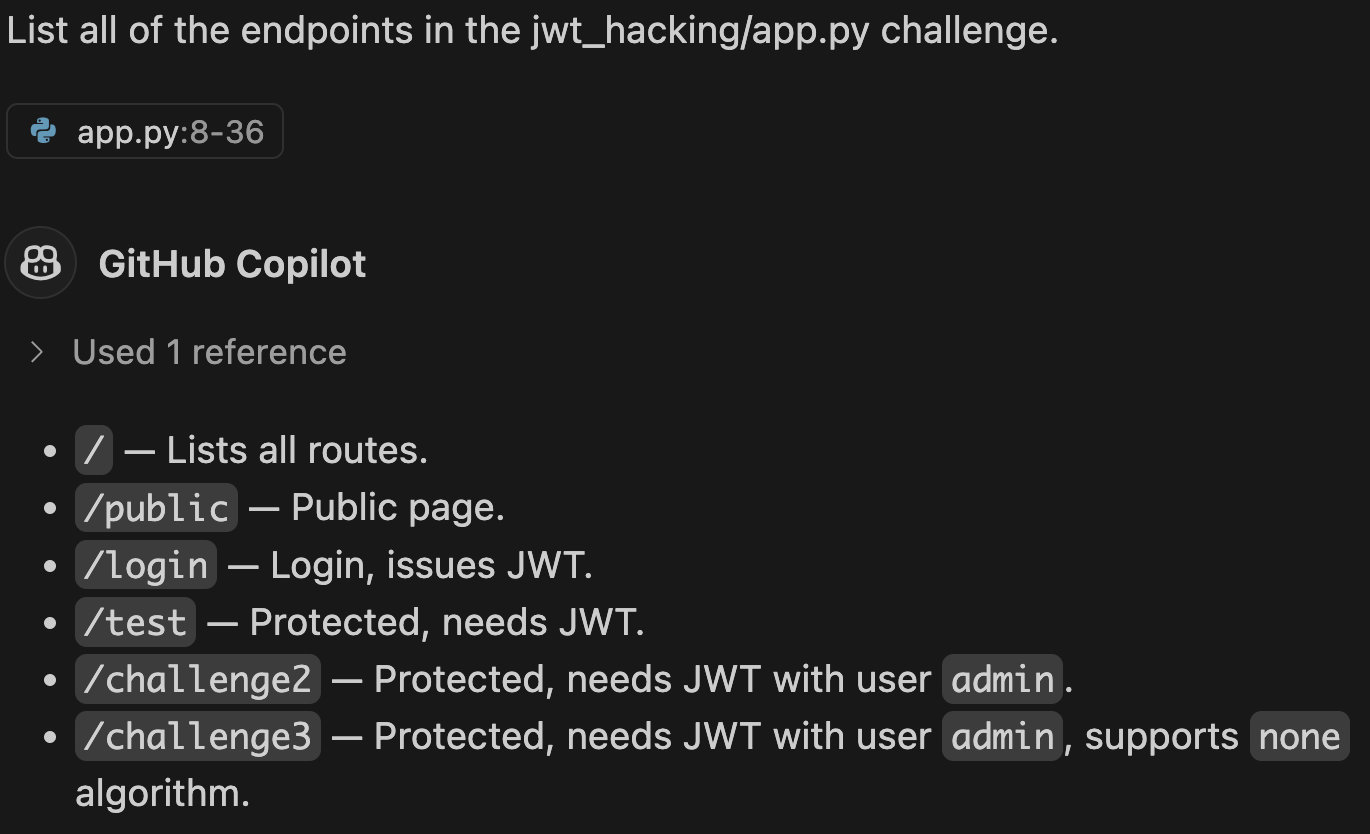
High-level architectural questions. Determining a project's file structure or tech stack often presents significant initial challenges. In complex codebases that utilize challenging-to-follow constructs (such as Golang channels), the lifecycle of calls can be especially complicated. Many AI tools excel at answering these questions, making it easier to start working on a new project. The primary tool that I use for high-level questions is DeepWiki. It's not perfect, but even if it is wrong, it guides me in the right direction. An example of this is shown in Figure 1.
When you are working deep inside a program's code, some parts may not be immediately clear. The purpose of a function or the way the code is written might be confusing. In such cases, tools like Cursor and CoPilot are highly effective for addressing narrowly focused code comprehension questions. These inquiries can be general, such as "Explain the functionality of the map method in JavaScript" or more context-specific, such as "What's the rationale for using map to perform type transformation within this block of code." Asking these types of questions prevents me from being stuck on a single issue for a long period of time.
A final application for enhancing code comprehension is a method of active self-assessment via quizzing. After studying a section of the code and becoming confident in my understanding, I'll ask the LLM a question and then attempt to answer it myself before it's generated. The goal is to see if my answer is the same as the AI's answer, similar to flashcards but dynamic. If the answers match, I feel confident in my understanding. If they do not, I work to understand the difference. This process helps gain confidence in my knowledge of the codebase.
Test Case Generation
Continue Reading →
Invocation Security: Navigating Vulnerabilities in Solana CPIsExternal
April 16, 2025



